

Kafka vs RabbitMQ: When operating on Microservices-based systems, Big Data professionals often face a dilemma of whether to use RabbitMQ or Apache Kafka for seamless message transfer. These two platforms have their own merits and may outperform each other in different scenarios. Moreover, Kafka and RabbitMQ utilize different architectures, which creates a significant contrast in their working methodology.
This post introduces both Apache Kafka and RabbitMQ along with their key features. It then provides an insightful comparison of the Kafka vs RabbitMQ discussion using four critical parameters. Read along to understand these two tools and decide which suits your work the best!
What is Apache Kafka?

Apache Kafka is one of the go to high performing event streaming tools for Big Data professionals. This open-source platform offers a robust message pipeline that consumes data from a multitude of sources in an incremental manner. This distributed platform combines multiple machines that collaborate to form a single cluster. Furthermore, Kafka deals in both online and offline data. It stores the ingested data on a disk and replicates it among central clusters for safekeeping.
The following features are responsible for Kafka’s popularity:
- High Scalability: Kafka can manage a significant volume of data in its data streams. Moreover, Kafka scales horizontally without any downtime in all four event dimensions, namely, Producers, Connectors, Processors and Consumers.
- Fault Tolerance: Kafka connector uses three strategies to handle situations of unexpected failures. Its Ignore, Fast-fail and Re-queue techniques are key for safeguarding your data.
- Durability: Kafka operates using a commit log distributed among multiple storages. This implies you will never face a situation of cascade failure, and your messages will persist on a disk for a long time.
- Performance: Kafka provides you with high publishing and subscription throughput. Moreover, it guarantees stable performance even when your incoming data is in Terabytes.
You can also learn how Kafka can be utilized with the Python programming language to build end-to-end Kafka Python Client Applications.
What is RabbitMQ?

RabbitMQ is one of the most promising message broker platforms that allows applications and services to exchange information without the hassle of maintaining protocols. Moreover, this tool offers an acknowledgement mechanism that, unlike other brokers, notifies you about the success or failure of your transmission. RabbitMQ relies on a smart broker architecture that manages messages at the consumer’s side. Furthermore, RabbitMQ deletes your data from its queues as soon as the consumer side processing is complete. Therefore, RabbitMQ provides you with a highly secure and seamless message exchange medium.
RabbitMQ offers you the following unique features:
- Clustering: RabbitMQ allows you to create a single broker by leveraging its multiple servers. This way, you can easily utilize its local network and create a message cluster.
- Federation: RabbitMQ has a unique federation model for servers requiring loosely connected messages and not wanting to operate via clusters. However, these connections are not reliable as clusters.
- Highly Available Queues: RabbitMQ empowers you to mirror message queues across multiple clusters. This way, you can enhance the reliability of your message transmissions and prevent data loss in case of hardware failure.
- Tracing: RabbitMQ provides you with trace support. This allows you to identify issues and debug your messaging system in case of unnatural server behaviour.
Comparing Kafka with RabbitMQ
This section provides you with insights to conclude the Kafka vs RabbitMQ discussion and decide on a tool that is suitable for your messaging needs. Kafka and RabbitMQ operate to provide the same service but using different methodologies. Therefore, you can get a better understanding of these tools by examining their Methodology, Messaging, Performance and Scalability.
Kafka vs RabbitMQ: Working Methodology
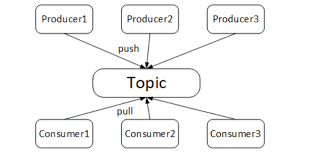
Kafka utilizes a pull model which operates on consumers’ requests for messages. According to these requests, Kafka groups messages into batches. Since the Kafka architecture contains partitions, the pull model is the optimal implementation methodology. Moreover, the pull model allows users to process batches of messages and achieve higher throughput. The Kafka logs also work to record the sequence of messages in each partition. This way, in situations of no contention between users, Kafka’s long pooling approach safeguards it from tight message loops and maintains its high throughput.
RabbitMQ relies on a push-based model that is prevalent in message distribution. This implies the RabbitMQ is an ideal tool if you are working with low latency messaging. This software provides you with robust parallelization for your message processing. RabbitMQ also ensures that your message processing does not change the order of incoming messages. Furthermore, you can easily distribute your message workload among various consumers and reap the benefits of RabbitMQ’s parallel processing.
Kafka vs RabbitMQ: Performance
In terms of performance Apache Kafka has a clear edge over RabbitMQ or any other message broker in the market. Since it leverages a sequential disk I/O (Input/Output) for performance enhancement, it is a viable option for managing message queues. Moreover, the Kafka architecture is capable of supporting millions of messages per second while using minimal resources. This makes Kafka, the most sought-after message broker tool among Big Data professionals.
RabbitMQ’s performance is also in the order of millions of messages per second. However, this tool requires a massive number of resources to manage such massive message quantities. This implies you can implement RabbitMQ for similar use cases as Kafka. Still, you might have to integrate it with other Apache Cassandra and other such tools to provide the required resources.
Kafka vs RabbitMQ: Scalability
The Kafka partitions are key for providing scalability and redundancy for your vast message sets. Kafka replicates its partition across multiple brokers. This way, even if one broker fails, you can serve the same partition to the clients via a different broker. Moreover, if Kafka were to store all its partitions for one topic with a single broker, the throughput of that specific broker might diminish.
Kafka overcomes this bottleneck by distributing the partitions among various brokers to enhance the message transmission throughput. Such a distribution requires either a key or the Round Robin method to provide users with access to multiple partitions. These approaches ensure that you can easily scale up your message quantity horizontally while enjoying the same throughput as Kafka.
RabbitMQ, on the other hand, offers you vertical scalability using multiple queues. It relies on a queue to perform message replications. This tool also deploys a Round-Robin mechanism to distribute the increasing load among queues to maintain the required throughput. It also ensures that no message queue gets overworked by the incoming load. Multiple consumers are able to access messages from multiple queues simultaneously. RabbitMQ’s vertical scalability is possible by adding more power to the message brokers. Kafka achieved the same results on a horizontal level by adding more machines.
Kafka vs RabbitMQ: Message Management

Kafka’s partitions allow you to maintain the original message orders. Moreover, since Kafka operates as a log, all of your messages are always present. You can ensure this by activating Kafka’s message retention policy. Furthermore, while using Kafka, you get to process the complete batch of messages. This implies that either the whole batch passes or all of the messages fail to complete a transmission.
On the other hand, RabbitMQ provides no provision for message ordering. Since this tool operates as a message queue, once it consumes your messages, they are no longer accessible. Furthermore, RabbitMQ does not offer atomicity. This implies that there can be situations where only a part of your messages will go through the transmission at once.
Conclusion
This post introduced you to Apache Kafka and RabbitMQ along with their key features. It further compared both of these platforms using four major parameters, Working Mechanism, Message Management, Performance and Scalability. Now, Kafka’s message retention abilities make it an ideal data streaming server. However, Kafka’s lack of message acknowledgment may be a bottleneck for certain users. Similarly, RabbitMQ’s guarantee of acknowledgment makes it a preferred message broker, but its performance still lags behind Kafka.
Therefore, both of these platforms have pros and cons, and you need to decide which tool will suit your work the most. Once you have finalized which tool to use, you will need to work on building data transmission pipelines to collect your data from various sources and store it in a suitable destination.
People Also Read:
New Azure and Microsoft 365 Certification Paths
What is Custom Software Development: Pros and Cons
Get Your Accs: 5 Ways to Build Your Network of Connections
Find the Best VPN for You in 2022
⚠ Article Disclaimer
The above article is sponsored content any opinions expressed in this article are those of the author and not necessarily reflect the views of CTN News



